©️2025 Created by Anuradha Samaranayake
Elevating Your Cloud Experience with Azure’s Reliability⏰

Ensuring Reliability in Azure Cloud: Key Strategies and Best Practices
In an era where businesses increasingly depend on cloud services, the demand for robust cloud solutions is paramount. Azure leads the charge in this domain, offering architects and technology leaders a platform where reliability is not merely a feature—it’s a fundamental principle.
Reliability in Azure 🔑
Reliability serves as the cornerstone of cloud architecture, reflecting a system’s strength in consistently delivering anticipated outcomes. It’s characterized not just by a service’s uptime but also by its strict adherence to defined Service Level Objectives (SLOs) and Service Level Agreements (SLAs). These benchmarks cover critical aspects, such as Recovery Time Objective (RTO)—the timeframe within which functionalities must be restored after a disruption—and Recovery Point Objective (RPO)—the maximum amount of data loss permitted during an outage before normal operations can resume. RPO applies not only to storage services but also to databases, caches, and queues.
In Azure, reliability translates to designing services that proactively address potential failures and quickly recover from them, minimizing disruptions for end-users. This is achieved through a shared responsibility model: Microsoft ensures the resilience of the underlying infrastructure, while customers thoughtfully design their solutions to harness these capabilities, integrating their business needs with Azure’s powerful features to maintain service continuity and meet or exceed RTO and RPO goals.
The Pillars of Cloud Reliability 🏛️
Azure’s architecture rests on several critical pillars that guarantee dependable service delivery:
Robust Infrastructure: Azure’s globally distributed network of data centers is equipped with advanced redundancy features, providing the resilient physical and virtual resources essential for high availability of applications.
Resilience by Design: The reliability of Azure stems from strategic design choices. Solutions built with resilience in mind can withstand operational pressures and recover swiftly from disruptions, ensuring minimal impact on service continuity.
Continuous Operations: Ongoing monitoring, timely incident management, and continuous system refinement are key to maintaining the operational health of Azure services. This dedication to continuous excellence strengthens service reliability and meets the evolving demands of cloud workloads.
Supporting Azure Reliability: Frameworks and Tools 🛠️
Azure’s commitment to reliability is backed by two essential frameworks: the Cloud Adoption Framework (CAF) and the Well-Architected Framework (WAF). These frameworks guide organizations through best practices and tools necessary for building and maintaining reliable cloud solutions.
Cloud Adoption Framework (CAF) 📚
The CAF offers comprehensive guidelines, blueprints, and best practices to ease the transition to the cloud. It provides insights into readiness and planning, ensuring that foundational decisions bolster reliability from the beginning. Key components include Azure Landing Zones, which set up networking, security, identity, and governance in alignment with Azure’s reliability principles.
Well-Architected Framework (WAF) 🏗️
The WAF concentrates on five essential areas: cost optimization, operational excellence, performance efficiency, reliability, and security. It empowers architects to design resilient systems by adhering to five principles of architectural excellence within Azure. The reliability pillar emphasizes the need for systems that are highly available, resilient, and capable of rapid recovery from failures.
Azure Service Reliability Features 🚀
Each Azure service comes with built-in features and tools tailored to enhance reliability. Notable tools include:
Azure Site Recovery: This service ensures business continuity by replicating workloads from primary to secondary regions, enabling quick failover and minimizing service disruptions during outages.
Azure Monitor and Application Insights: Together, these services deliver advanced monitoring, analytics, and diagnostics capabilities, providing real-time operational intelligence that supports swift and proactive incident management.
Azure Automation: Designed to reduce manual intervention, Azure Automation streamlines process automation, update management, and configuration features, enhancing service reliability by minimizing human error.
Architecting for Reliability 🏗️✨
By leveraging strategic design choices, Azure enables systems to quickly recover from disruptions while ensuring continuous operations—demonstrating Azure’s commitment to uninterrupted service excellence based on reliability design principles.
Azure Landing Zones: The Foundation for Reliable Cloud Operations 🏞️
Azure Landing Zones are customizable environments that adhere to Microsoft’s Cloud Adoption Framework. They offer a structured setup process that incorporates best practices for security, compliance, and governance—forming a solid foundation for your cloud journey. When setting up your landing zones, consider these reliability-focused factors:
Network Topology: Utilize Azure’s robust networking features to design a topology that emphasizes redundancy and failover capabilities.
Resource Organization: Structure your resources for coherence and ease of management, aligning them with your reliability objectives.
Identity and Access Management: Implement stringent security controls to prevent unauthorized access that could compromise reliability.
Governance: Establish policies that enforce operational consistency and compliance, adding another layer of reliability protection.
Mission-Critical Reliability: Ensuring Resilience at Scale 🛡️⚙️
For mission-critical services where stakes are high, Azure provides a powerful toolkit and strategic methodologies to ensure resilience:
Geo-Redundancy: Implementing a multi-region architecture is essential for mission-critical applications. Azure allows the distribution of services across various geographic locations, protecting against regional failures and enhancing fault tolerance.
Disaster Recovery: Azure Site Recovery offers seamless replication services for virtual machines (VMs), enabling swift failovers to alternate regions and ensuring minimal downtime for critical applications. The replication granularity allows businesses to meet their specific RTO or RPO targets.
Auto-Scaling: Azure’s auto-scaling capabilities dynamically adjust resource counts to meet workload demands without manual intervention, essential for performance during usage spikes and optimizing resource use during quieter times.
Monitoring and Diagnostics: With tools like Azure Monitor and Azure Application Insights, organizations gain real-time visibility into their operational landscape, allowing for proactive issue detection and rapid resolution—crucial for mission-critical systems.
By weaving these practices into the architectural framework, mission-critical services on Azure can achieve continuous reliability, ensuring consistent service levels that foster user trust and satisfaction. For further details, refer to Mission Critical Guidance.
Reference Architecture 🔍🏗️
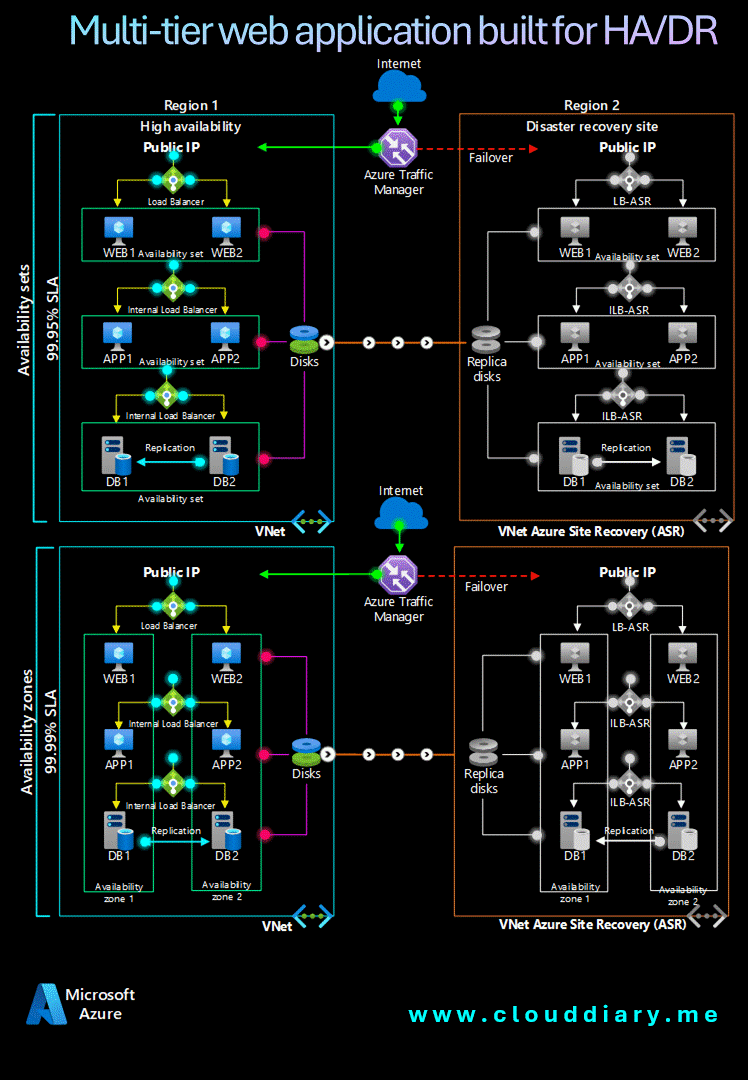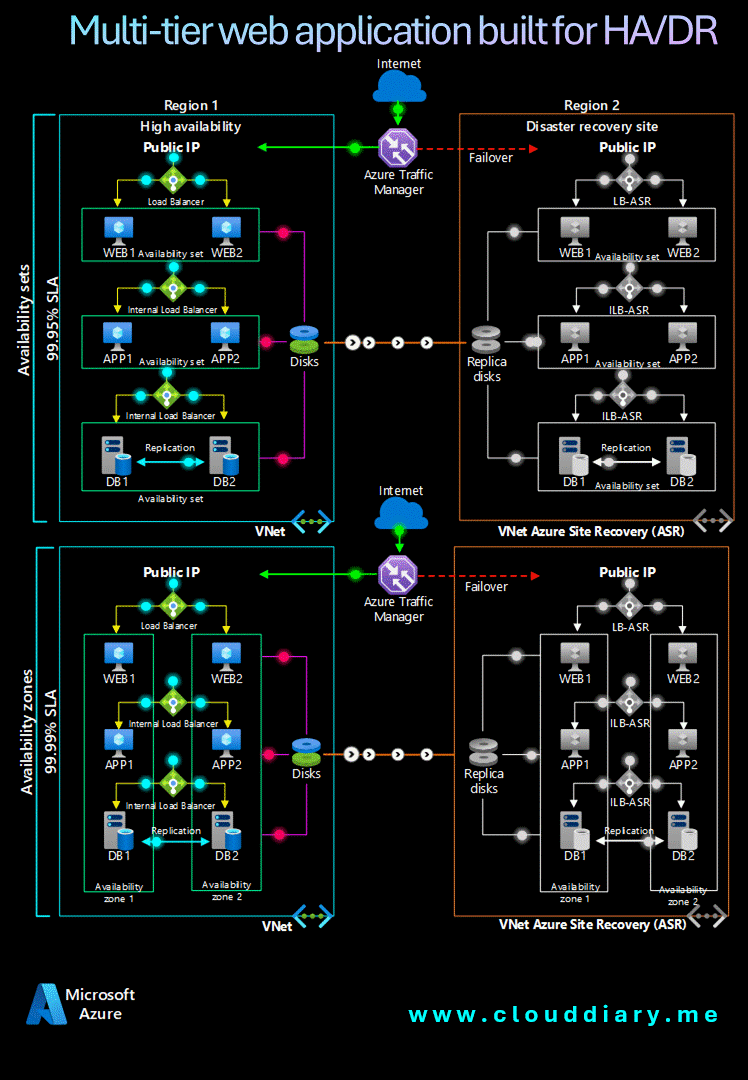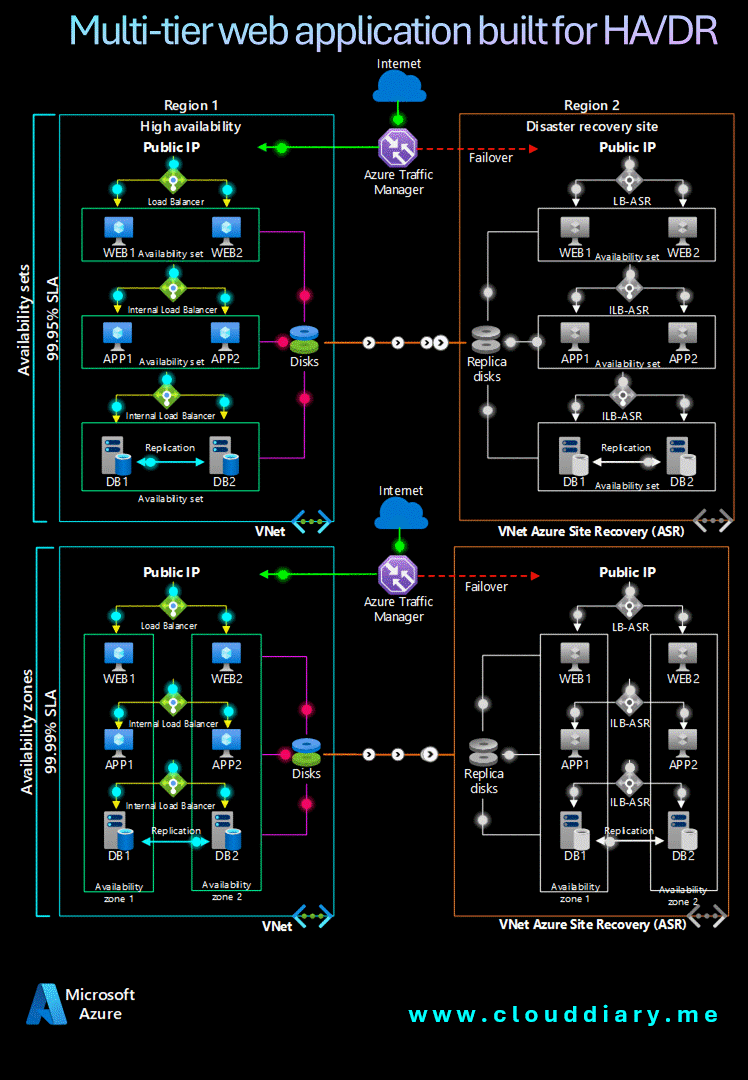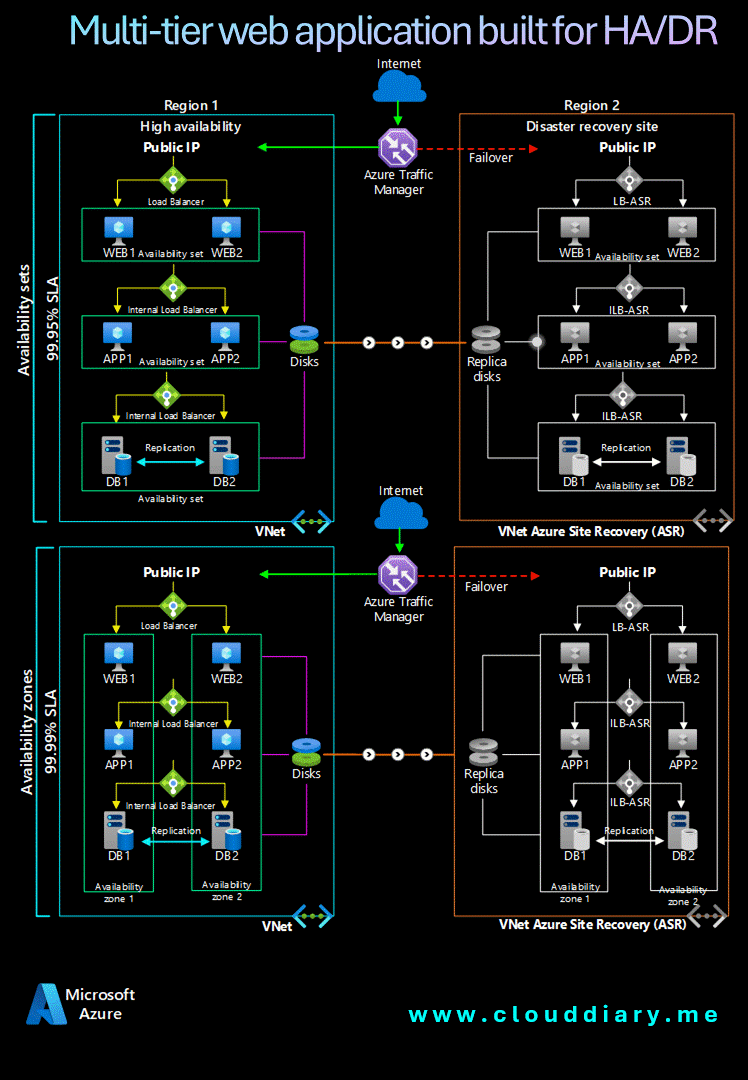
Achieving reliability in the cloud is about integrating tools and services into an architecture that embodies resilience and fault tolerance. A strategic approach to designing a reliable Azure architecture requires a holistic view that encompasses compute, storage, database, and networking resources.
Let’s explore a reference architecture that illustrates Azure’s reliability principles in action, demonstrating how various Azure services interconnect to create a dependable cloud infrastructure that ensures seamless, continuous operations.
Components 🖥️📊
- Availability sets ensure that the VMs you deploy on Azure are distributed across multiple isolated hardware nodes in a cluster. If a hardware or software failure occurs within Azure, only a subset of your VMs are affected and your entire solution remains available and operational.
- Availability zones protect your applications and data from datacenter failures. Availability zones are separate physical locations within an Azure region. Each zone consists of one or more datacenters equipped with independent power, cooling, and networking.
- Azure Site Recovery allows you to replicate VMs to another Azure region for business continuity and disaster recovery needs. You can conduct periodic disaster recovery drills to ensure you meet the compliance needs. The VM will be replicated with the specified settings to the selected region so that you can recover your applications in the event of outages in the source region.
- Azure Traffic Manager is a DNS-based traffic load balancer that distributes traffic optimally to services across global Azure regions while providing high availability and responsiveness.
- Azure Load Balancer distributes inbound traffic according to defined rules and health probes. A load balancer provides low latency and high throughput, scaling up to millions of flows for all TCP and UDP applications. A public load balancer is used in this scenario to distribute incoming client traffic to the web tier. An internal load balancer is used in this scenario to distribute traffic from the business tier to the back-end SQL Server cluster.
By adhering to these architectural principles, you can design a robust system that inherently incorporates resilience and reliability into every layer. A well-structured architecture is vital for achieving high reliability on Azure, serving as a blueprint for integrating resilience principles into your applications.
Azure Verified Modules for Reliability 📦
Azure Verified Modules (AVM) aim to establish standards for high-quality Infrastructure-as-Code modules. AVM is a common code base that assists customers and partners in accelerating consistent solution development and cloud-native delivery by codifying Microsoft guidance (WAF) and best practice configurations.
This article highlights a sample AVM module designed for reliable Azure-to-Azure replication for disaster recovery. It supports replication across regions or within the same region. You can find it on GitHub – Azure/terraform-azurerm-avm-ptn-bcdr-vm-replication. This module replicates virtual machines within Azure from a source to a target location while managing all replication policies and resource configurations.
Conclusion
Embarking on your reliability journey with Azure signifies a commitment to operational excellence. By leveraging Azure’s global infrastructure, proactive design strategies, and a comprehensive suite of tools and best practices, you can pave the way for reliable, scalable, and resilient cloud environments.