©️2025 Created by Anuradha Samaranayake
Strategies & best practices to keep your Azure environment Robust & Reliable

Ensuring High Availability in Azure
Best Practices and Strategies to Keep Your Azure Environment Robust and Reliable
In today’s digital-first world, "down-time" isn't just an inconvenience; it's a critical failure. Ensuring your applications and services remain available and resilient is paramount. Today, I want to write about the strategies for achieving high availability (HA) and disaster recovery (DR) in Azure. Microsoft provides a powerful suite of tools, and by architecting our solutions correctly, we can build environments that are both robust and reliable. Let's dive in. 🚀
1. Use Azure Availability Zones 🌐
This is the foundation of high availability. Availability Zones (AZs) are physically separate data centers within a single Azure region, each with independent power, cooling, and networking. By deploying your VMs or services across multiple AZs, you ensure that a localized failure (like a fire or power outage in one building) won't take your entire application offline. For critical workloads, always deploy "zone-redundantly."
2. Opt for Premium or Standard SSDs 💾
The storage you choose directly impacts your VM's reliability. To get the highest Service Level Agreement (SLA) for a single VM, you must use Premium SSDs or Ultra Disks. Standard HDDs are cheaper but offer lower performance and a weaker SLA. For any production environment, Premium SSDs provide the superior performance and reliability needed for high availability.
3. Implement Load Balancers ⚖️
A load balancer is non-negotiable for HA. It distributes incoming traffic across multiple backend resources, like VMs in a scale set. If one instance fails a health probe, the load balancer instantly stops sending it traffic, redirecting users to healthy instances without any service interruption. Azure Load Balancer (Standard SKU) is zone-redundant and provides this critical health-checking and traffic distribution.
4. Utilize Azure Traffic Manager & Front Door 🌍
For global applications, you need global redundancy. Azure Traffic Manager is a DNS-based load balancer that routes users to different regions (e.g., nearest, best performance, or failover). For modern web apps, Azure Front Door is often the superior choice. It's a global HTTP/S load balancer that provides instant failover, caching, and a powerful Web Application Firewall (WAF) to protect against common exploits and large-scale DDoS attacks at the network edge.
5. Leverage Azure Site Recovery 🔄
This is the core of traditional Disaster Recovery. Azure Site Recovery (ASR) automates the replication of your on-premises or Azure VMs to a secondary Azure region. It continuously copies changes, and in the event of a primary site disaster, you can "failover" to the secondary region to bring your services back online within your defined RTO/RPO, ensuring business continuity.
6. For Web Apps, Use Azure App Service 🌐
Why manage VMs when you don't have to? Azure App Service is a fully managed PaaS (Platform-as-a-Service) for web apps. By deploying your application to an App Service Plan, you get built-in load balancing, auto-scaling, and patching. For HA, you can easily deploy to multiple regions and use Azure Front Door to manage global traffic, or deploy within a single region using a zone-redundant App Service Environment.
7. Use Azure SQL Managed Instance & DB 🗄️
Your database must be as resilient as your application. Azure's PaaS databases are built for this. Azure SQL Database and SQL Managed Instance (especially in Business Critical tiers) offer built-in high availability. For DR, you can configure Auto-Failover Groups, which automatically replicate your database to another region and manage the failover process if your primary region goes down.
8. Deploy Virtual Machine Scale Sets 🖥️
For VM-based workloads, you should rarely deploy a single VM. Virtual Machine Scale Sets (VMSS) allow you to create and manage a group of load-balanced VMs. The number of VM instances can automatically scale up or down based on demand (autoscale). When integrated with Availability Zones, VMSS automatically spreads your instances across zones, providing a highly resilient and scalable compute layer.
9. Implement Geo-Redundancy for Storage 🌎
Your data is your most critical asset. Azure Storage provides multiple redundancy options. Locally-Redundant Storage (LRS) is the minimum, but for HA, you should use Zone-Redundant Storage (ZRS). For DR, Geo-Redundant Storage (GRS) or Read-Access Geo-Redundant Storage (RA-GRS) replicates your data to a secondary region hundreds of miles away, protecting it from a regional disaster.
10. Use Azure Backup Solutions 🛡️
Replication is for HA, but backups are for data integrity (e.g., protecting against ransomware or human error). Azure Backup is a simple, secure, and cost-effective solution. You can back up VMs, SQL databases, and file shares. With the Azure Backup Center, you get a single pane of glass to manage your entire backup estate, ensuring your data is recoverable and your backup policies are compliant.
11. Implement NSGs and Azure Firewall 🔒
Availability isn't just about failures; it's about security. A DDoS attack or a breach can take your service offline just as fast as a hardware failure. Network Security Groups (NSGs) are your first line of defense, filtering traffic to and from your subnets. Azure Firewall (especially Premium) provides advanced, stateful network protection, including threat intelligence-based filtering and IDPS, to block malicious traffic before it ever reaches your applications.
12. Use Azure Monitor and Application Insights 📊
You cannot guarantee the reliability of a system you aren't monitoring. Azure Monitor and Application Insights are essential. They provide comprehensive monitoring and diagnostics, helping you detect and diagnose issues *before* they impact users. Set up alerts on key metrics (like CPU, response time, or error rates) and configure automated responses to ensure quick mitigation of potential problems.
13. Regularly Update and Patch Your Systems 🔄
An unpatched system is an unreliable system. Vulnerabilities can be exploited to cause downtime or data loss. While Azure PaaS services manage this for you, you are responsible for your IaaS VMs. Use Azure Update Manager (the evolution of Update Management Center) to automate and manage OS updates for your Azure VMs and even on-premises servers via Azure Arc.
14. Implement Redundant Internet Connections 🌐
For critical hybrid workloads that connect your on-premises data center to Azure, a single internet connection is a single point of failure. Use Azure ExpressRoute for a dedicated, private connection. For maximum reliability, configure a redundant ExpressRoute circuit, or use a site-to-site VPN as a cost-effective failover path in case your primary ExpressRoute connection fails.
15. Conduct Regular Disaster Recovery Drills 🧰
A disaster recovery plan that hasn't been tested is not a plan; it's a theory. Regularly testing your DR plan is the *only* way to ensure it works when you need it most. Use Azure Site Recovery's "Test Failover" feature, which creates an isolated network bubble for you to test your failover process without impacting your production environment. This practice helps you identify gaps and ensures your team is prepared to respond effectively.
Architecture Example: Multi-Region Web App
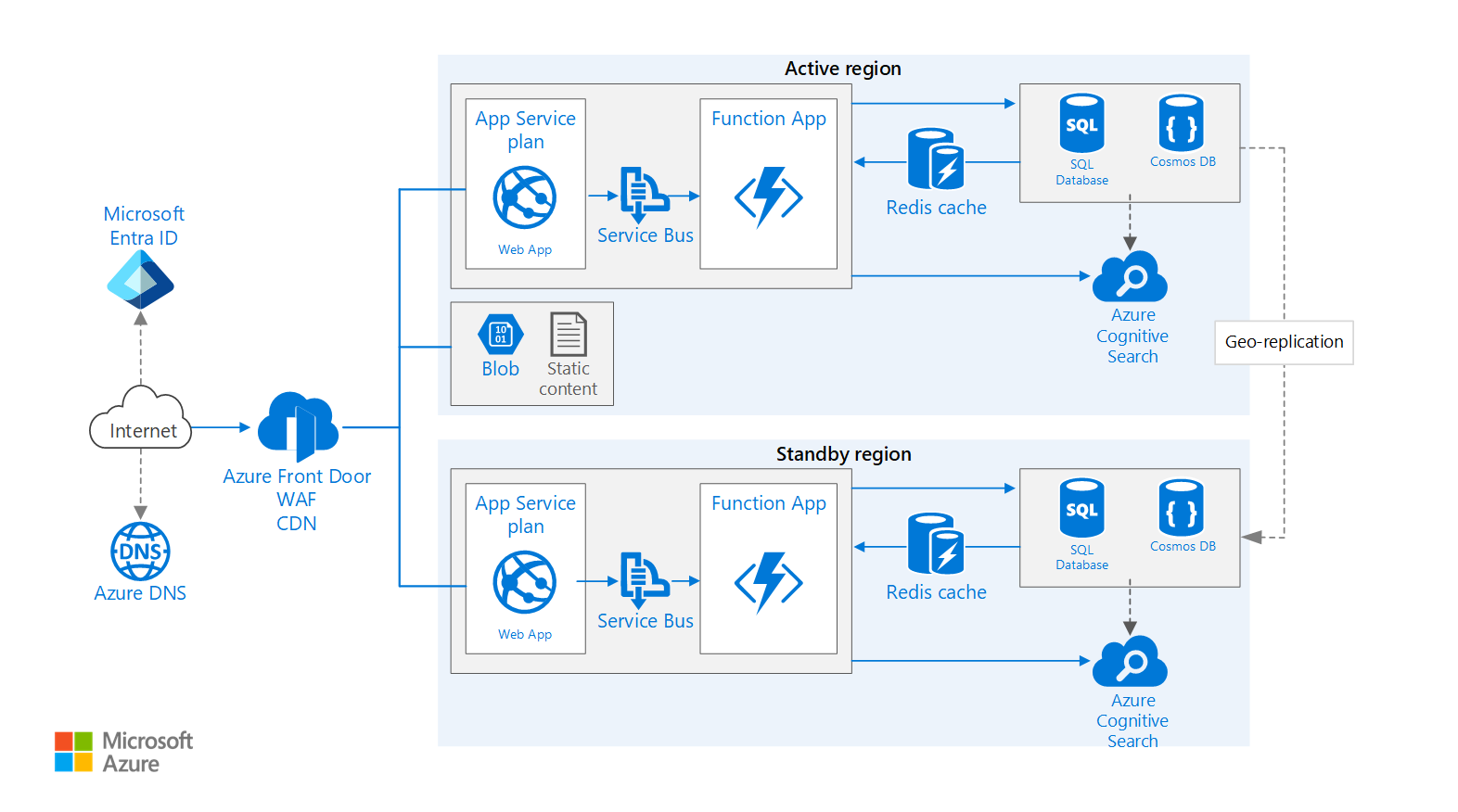
This diagram shows a robust, multi-region architecture designed for high availability. Here’s how it works:
- 🌐 Azure Front Door: This is the global entry point. It provides a Web Application Firewall (WAF) and DDoS protection to block malicious attacks at the edge. It uses priority-based routing to send all traffic to the Primary Region.
- 🌍 Primary & Secondary Regions: The application is deployed identically to two separate regions. If Azure Front Door detects that the Primary Region is unhealthy or unavailable, it automatically reroutes all traffic to the Secondary Region with no manual intervention.
- 🔄 Geo-Replication: Critical data in Azure SQL Database and Azure Storage is geo-replicated from the primary to the secondary region, ensuring data is available after a failover.
Achieving high availability in Azure involves leveraging a combination of these powerful tools, services, and best practices. By implementing these strategies, you can ensure that your applications and services remain resilient, responsive, and available even in the face of unforeseen events. 🌟 Remember, high availability and disaster recovery are not just about technology but also about planning and architecture. Make sure to design your solutions with redundancy and failover in mind to keep your business running smoothly.
Hey! Thanks for reading my blog 🙌
If something still feels a bit complex, don’t worry — I’ve got you covered.
Just enter any technical term from this article (like “Azure Front Door,” “Auto-Failover Groups,” or “Availability Zones”), and my AI will explain it in simple, easy-to-understand language.